Please Stop This Thing, I Want to Get Off: Living the Merry-Go-Round of FAIL
There’s this pattern of application failure I’ve ended up dealing with a lot over the years. Stop me if you’ve heard this one before.
Our scene opens with a multi-tiered client-server application, let’s say, for the purpose of argument, that it’s a web app. There are web servers in the front, usually with some sort of load balancer in front of them, then maybe a middle tier application server (SOAP, J2EE, that kind of thing), and some kind of shared state/storage at the back, let’s call it a SQL database.
The app is functional, but not fast. Every once in a while, some developer might be assigned to try to make something perform a little better, but mostly everyone’s piling on new features.
Then one day, the app just dies. No one can use it, customers are complaining, everyone starts looking around, people poke some, database traces are initiated, and eventually they get it to come back on line. Everyone pats each other one the back, they send off an email to management explaining how they fixed the problem, and live happily ever after.
That is until tomorrow, or that afternoon, or the next week, and then it happens again. And someone (often several someones) make changes that seem like a good idea in the heat of the crisis - they weren’t caught completely by surprise this time, so they notice it earlier and have more time to poke and change. The site comes back up. They declare victory and move on. Until it happens again. Each time, they make the change that fixes the problem. Each time, they assign a root cause and justify why we really fixed it this time. Each time it comes back again.
Here’s what’s happening:
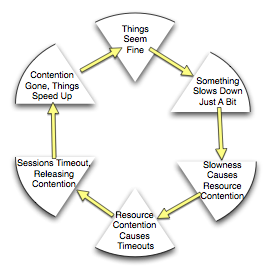
The system is at what physicists call an unstable equilibrium. Many enterprise IT applications live their lives this way. Think of a pencil balanced on its point - it’s possible for it to balance that way, but as soon as something blows on it, over it goes.
All it takes is one little push - a network hiccup, a SAN slowdown, temporary traffic spike, some user runs a report during prime time that they usually only run at night - could be any one of dozens of things. This starts the wheel going around. Things start to get slower, and because there’s a shared back-end, when the back-end gets slow, everything that touches the back-end (which often everything) gets slow.
Next phase, normal things that used to be able to run just fine as each other, can’t. Maybe the query runs longer which means it’s holding its rows locked longer which causes the next query to block, etc. Maybe the network had to retransmit the data more than once because a pipe got full and a packet got dropped. Maybe the disk queue got too large, causing disk access to take too long, which caused the queue to get larger. It can be different every time. But what is happening at this point is called a positive feedback loop. The slower things get, the more it makes things slower. This is fatal.
At some point in the downward spiral, a threshold is hit. Maybe the load balancer declares all the web servers dead and stops sending them traffic. Maybe the database gets slow enough that the web servers lose their connections to the DB. Maybe the DB reboots. Could be anything.
Now that there’s no more traffic, everything that’s fighting for a resource will either time out and die, or get the resource it wants. The resources are no longer being fought over. Things become calm again.
The front end servers reconnect. Everything seems fast again. People believe that whatever they did fixed the problem.
But usually, nothing really got fixed and it’s just a mater of time before it starts again. And quite often, all the cowboys running around changing things during the outage without testing or evidence (often saying “well, we can’t make it worse, right?”) just make the equilibrium a little less stable, so it takes even less of a push to start it rolling again. Continue this for a while, and things will get so unstable that there’s no equilibrium, and the system can’t even take what used to be normal traffic.
The only long-term solution I’ve found, is patience. when the site comes back up, collect whatever information you gathered during the outage, decide on 2 things:
-
What is the ONE AND ONLY ONE THING you are going to change if this happens again, and
-
What other data to you want to try to collect on the next outage?
Then you get your scripts ready and hope it’s really fixed, but if you’re wrong, you know you still have a problem, you make your SINGLE SOLITARY CHANGE, gather what data you can, and once it comes back up, you hope your one change fixed it. If not, you better have a new plan for your next change queued up by then. It might even get worse (you are measuring your app’s performance, right)? In which case, you need to reverse your one change that you made (you did make a back-out plan, right)?
One more tip: Try not to focus on the thing that started the slow down in step 1. A lot of teams spend hours or days trying to identify what the SAN hiccup was caused by. They think of this as the root cause - but it’s not - it’s just the catalyst. The root cause is the inherent instability of the system. That’s less pleasant to want to believe, because it’s much harder to fix, but the sooner you start facing reality, the sooner you can apply the resources to the right things and break the cycle.
This is a survivable situation, both as an individual and as a team. It sucks, and if you make changes all over the place, you’ll have no control over whether things get better or worse. So calm down, think, measure, change ONE THING AT A TIME measure again, and roll back if you need to. You CAN get off the Merry-Go-Round of FAIL - you just have to be patient and deliberate.
And whatever you do, try not to fall off the horsey, will you? It’s unseemly.